
Autor: Bjoern Koester
v1.04
Diese Ausarbeitung zum Thema I/O-Grundlagen entstand Anfang 1998 im Rahmen eines Vortrags im
Ausbildungsgang zum staatlich geprüften Mathematisch-technischen
Assistenten (kurz: MaTA) an der Lichtenberg-Schule (ehem.
OSGO) in Kassel.
Eine aktuelle Version dieses Dokuments liegt immer unter https://www.bjoern-koester.de/iogrundlagen/index.html.
Einleitung
Im Laufe der Computer-Evolution hat sich ein Wandel vollzogen. Aus der ursprünglichen ,,Rechenmaschine``, die dem Zweck diente, Rechenoperationen automatisiert durchzuführen, wurde eine ,,Multimedia-Maschine``, die aus fast keinem Bereich des menschlichen Lebens mehr wegzudenken ist. Die Benutzerschnittstelle muß heute den größten Ansprüchen genügen. Enorme Datenmengen werden zwischen Benutzer und Computer ausgetauscht. Folglich ist man daran bestrebt, die größtmögliche Effizienz beim Datenaustausch zu erreichen. Es werden daher im Rahmen dieses Referates verschiedene Konzepte vorgestellt, doch zunächst sollen die dafür nötigen Grundlagen vermittelt werden.
Das I/O-Konzept
Man faßt das gesamte Gebiet, in dem es um die Ein- und Ausgabe von Informationen in Form von Daten geht, unter der englischen Bezeichnung Input/Output (kurz: I/O) zusammen. Dieses Thema ist sehr komplex. Um seine Bedeutung und Vielseitigkeit zu zeigen, unterteilen wir es in drei wesentliche Bereiche.
- 1.
- Es geht zum einen um das grundlegende Prinzip. Dieses beschreibt die Strategie, durch die ganz allgemein Daten in den Computer und zurück zum Benutzer gelangen. Wir wollen uns mit den drei wesentlichen Strategien PIO, Interrupts und DMA auseinandersetzen.
- 2.
- Zum anderen geht es um die Schnittstelle, die Hardware also, die den Datentransport übernimmt.
- 3.
- Und schließlich geht es um die für den Benutzer greifbaren I/O-Geräte.
Diese wandeln Informationen in Daten und umgekehrt. Sie leisten somit
die notwendige Codier- und Decodierarbeit (z.B. analog
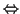 digital). Dies sind z.B. der Monitor (Output), die
Tastatur (Input), Maus (Input), Festplatte (Input/Output) oder Floppy
(Input/Output). In der Fachsprache ist auch häufig die Rede von Peripheriegeräten.
digital). Dies sind z.B. der Monitor (Output), die
Tastatur (Input), Maus (Input), Festplatte (Input/Output) oder Floppy
(Input/Output). In der Fachsprache ist auch häufig die Rede von Peripheriegeräten.
Von der Beschreibung der Art und Weise wie Schnittstellen und deren Endgeräte, die Peripheriegeräte, beschaffen sind, wird hier nicht näher eingegangen.1 Im folgenden wollen wir uns mit dem zuerst genannten Punkt, den verschiedenen Strategien zur Ein- und Ausgabe von Daten beschäftigen.
Anforderungen an das System
Damit die Übermittlung zwischen Computer (Hauptspeicher) und seiner Peripherie korrekt ablaufen kann, stellen wir an das System, auf dem das I/O-Konzept angewandt werden soll, folgende Anforderungen:
- Hauptspeicherverwaltung (bereits besprochen worden) 2. Nötig, damit über das Adreßregister der CPU auf den Hauptspeicher zugegriffen werden kann.
- Absicherung vor eventuell auftretenden Übertragungsfehlern. (Vgl.
Abschnitt
![[*]](verweis.gif) ).
). - Aktivierung und Steuerung des Datentransports. Es muß eine Möglichkeit gegeben sein, den Datentransport von oder zu einem Peripheriegerät aktivieren zu können.
Handshaking
Bei der Datenübermittlung ist eine gewisse Abstimmung zwischen Sender und Empfänger nötig, um sicher zu gehen, daß der Transport der Daten fehlerfrei abläuft. Stellen wir uns vor, wir schicken einen sehr wichtigen Brief per Post, wissen aber nicht genau, wann und ob er überhaupt den Empfänger erreicht. Das I/O-Konzept sieht daher eine Absicherung seiner Datenübermittlungen vor.
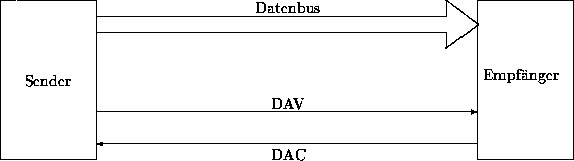
Abbildung ![]() zeigt die schematische Implementierung
des Handshakingverfahrens. Zwischen Sender und Empfänger der Daten befindet
sich in erster Linie der Datenbus, auf dem die Daten vom Sender dem Empfänger
zugänglich gemacht werden. Hinzu kommen zwei (Signal-)Leitungen, die mit
DAV (data valid, Daten gültig) und DAC (data accepted, Daten akzeptiert)
bezeichnet werden. Sie haben die Bedeutung von sogenannten Flags, einer
Art boolescher Variable, die entweder 0 (kein Signal) oder 1 (Signal)
ist. DAV kann jeweils nur vom Sender und DAC vom Empfänger gesetzt werden.
Sobald sich die Daten vom Sender auf dem Datenbus befinden, läßt er dies
den Empfänger durch Setzen des DAV-Signals auf 1 wissen. Anschließend
erkennt der Empfänger das DAV-Signal und beginnt, die Daten einzulesen.
Bei erfolgreichem Empfang der Daten wird das DAC-Signal ebenfalls auf
1 gesetzt. Was danach passiert, ist in dem einfachen Handshaking-Modell
nicht definiert. Aus diesem Grund hat man es für den praktischen Gebrauch
erweitert.
zeigt die schematische Implementierung
des Handshakingverfahrens. Zwischen Sender und Empfänger der Daten befindet
sich in erster Linie der Datenbus, auf dem die Daten vom Sender dem Empfänger
zugänglich gemacht werden. Hinzu kommen zwei (Signal-)Leitungen, die mit
DAV (data valid, Daten gültig) und DAC (data accepted, Daten akzeptiert)
bezeichnet werden. Sie haben die Bedeutung von sogenannten Flags, einer
Art boolescher Variable, die entweder 0 (kein Signal) oder 1 (Signal)
ist. DAV kann jeweils nur vom Sender und DAC vom Empfänger gesetzt werden.
Sobald sich die Daten vom Sender auf dem Datenbus befinden, läßt er dies
den Empfänger durch Setzen des DAV-Signals auf 1 wissen. Anschließend
erkennt der Empfänger das DAV-Signal und beginnt, die Daten einzulesen.
Bei erfolgreichem Empfang der Daten wird das DAC-Signal ebenfalls auf
1 gesetzt. Was danach passiert, ist in dem einfachen Handshaking-Modell
nicht definiert. Aus diesem Grund hat man es für den praktischen Gebrauch
erweitert.
Fully Interlocked Handshaking
Wenn im folgenden von Handshaking die Rede ist, so ist damit stets das
erweiterte Handshaking gemeint. In der Fachliteratur findet man es häufig
unter der Bezeichnung ,,fully interlocked handshaking`` (vollverschränkt).
Der Unterschied zwischen dem einfachen und erweiterten Handshaking liegt
darin, daß das einfache Verfahren lediglich eine Art Empfangsbestätigung
zurückliefert, während das erweiterte Verfahren eine zweiseitige Bestätigung
verlangt. Es kann der nächste Schritt der Datenübertragung (z.B. Datenpakete
in Bytes) erst dann erfolgen, wenn der vorangegangene Schritt bestätigt
(,,acknowledged``) worden ist. Dies ist erst dann der Fall, wenn alle
beiden Signale wieder auf 0 stehen. Kurz: Der Empfänger bestätigt das
DAV-Signal durch sein DAC-Signal, während der Sender die Bestätigung des
DAC-Signals durch Zurücksetzen von DAV signalisiert.
| Abbildung: Fully Interlocked Handshaking aus Sicht der Signalabläufe |
 |
Abbildung ![]() veranschaulicht den Zusammenhang:
veranschaulicht den Zusammenhang:
- (A)
- Der Sender legt sein erstes Datenbyte an den Datenbus.
- (B)
- Indem der Sender das Signal DAV auf 1 setzt, wird der Datentransport als gültig aufgefaßt und der Empfänger dazu veranlaßt, den Empfang des Signals zu prüfen.
- (C)
- Jetzt bestätigt der Empfänger den Empfang der Daten auf dem Datenbus, indem DAC auf 1 gesetzt wird.
- (D)
- Der Sender deaktiviert daraufhin den Transport, setzt DAV auf 0 zurück und wartet, bis der Empfänger wieder seine Empfangsbereitschaft signalisiert.
- (E)
- Durch DAC=0 erklärt sich der Empfänger wieder empfangsbereit und der Sender kann sein nächstes Datenbyte, falls verlangt, an den Datenbus legen.
In der Praxis wird das Handshaking durch eigene Hardware ersetzt. Der
Prozessor selbst befaßt sich in der Regel nicht mit der Aufgabe des Handshaking.
Es gibt jedoch Sonderfälle, in denen er eingreifen sollte. So z.B. wenn
der Sender DAV signalisiert, aber der Empfänger das DAC-Signal nicht setzen
kann. Dann ist entweder die Hardware fehlerhaft oder der Empfänger ist
nicht aktiviert. Normalerweise, d.h. in modernen Systemen, wird gleichzeitig
mit dem Setzen des DAV-Signals auch ein Timer gestartet. Wird eine bestimmte
Zeit überschritten, so muß an den Prozessor ein Fehler (Timeout)
gemeldet werden. Dies geschieht über Interrupts (vgl. Abschnitt ![]() ). In den früheren Systemen fehlte ein solcher Mechanismus,
was dazu führte, daß der Sender beliebig lange auf den gesetzten DAC gewartet
hatte und den Rechner ,,aufhing``.
). In den früheren Systemen fehlte ein solcher Mechanismus,
was dazu führte, daß der Sender beliebig lange auf den gesetzten DAC gewartet
hatte und den Rechner ,,aufhing``.
Abgesehen von der Gewißheit, daß der Empfänger (beispielsweise die Peripherie) die Daten erhalten hat, ist das Handshaking auch noch aus einer anderen Sichtweise sinnvoll. Bei langsameren Peripheriegeräten wird die Datenübertragung solange aufgehalten, bis das I/O-Gerät seine Bereitschaft mittels DAC=0 signalisiert.
Jetzt ist auch sicherlich einleuchtend, warum dieses Verfahren ausgerechnet ,,Handshaking`` heißt. Sozusagen ,,geben sich Sender und Empfänger die Hand``.
Programmierte I/O
Unter der programmierten I/O, prozessorgesteuerten I/O, PIO versteht man die Initiierung des Datentransports von der Software - und damit von der CPU - aus. Die Umsetzung benötigt einen minimalen Anteil von Hardware. Es geht darum, an die Anschlüsse der Geräte (die sogenannten Ports) heranzukommen, sie zu adressieren.
I/O-Ports
Die Peripheriegeräte sind über ihre Schnittstellen mit dem Systembus3 verbunden. Für den Prozessor sollen die internen Register der Schnittstellen bzw. der Peripheriegeräte selbst möglichst leicht erreichbar sein. Dazu faßt man alle Register zu einem zusammenhängenden Speicherblock zusammen. Ein Teil des verfügbaren Speicherraums (und damit auch des Adreßraums) wird speziell für die Peripheriegeräte ein maximal 64 Kbyte großer Speicherbereich reserviert, den man als I/O-Bereich bezeichnet. Konkrete I/O-,,Speicher``-Adressen heißen I/O-Ports. In der Regel verfügt ein Gerät über aneinanderhängende Port-Adressen (sie werden üblicherweise in Hexadezimalschreibweise angegeben). Die I/O-Ports stellen eine Schnittstelle zu den entsprechenden Registern der angeschlossenen Peripheriegeräte dar. Üblicherweise werden die Adressen hardwareseitig direkt durch die Peripherieschnittstellen festgelegt. Es befinden sich meist DIP-Schalter auf den Schnittstellenkarten, die eine Auswahl mehrerer ,,Basisadressen`` für die I/O-Ports erlauben. Eine Doppelbelegung mehrer Geräte über eine Adresse führt daher unweigerlich zu Konflikten.
Memory-Mapped I/O
Bei der Memory-Mapped I/O-Methode4 (auch oft als speicherbezogene Adressierung bezeichnet) befindet sich der I/O-Bereich im Arbeitsspeicher. Für den Speicher und den I/O-Bereich wird der gemeinsame Adreßraum verwendet. Daher wird aus Sicht des Programmierers nicht unterschieden, ob auf eine reale Stelle im Arbeitsspeicher oder auf einen I/O-Port zugegriffen wird. Die Adressierungsbefehle auf den Speicher bzw. auf die Ports sind folglich identisch. Vorteilhaft ist die Möglichkeit, mit der gesamten Palette an Maschinenbefehlen auf die Geräteregister - und damit auf die Peripheriegeräte selbst - zugreifen zu können. Außerdem werden keine externen Busleitungen gebraucht, die für den jeweiligen Zugriff bestimmt sind. Die Firma MOTOROLA verwendet ausschließlich dieses Konzept.

Der Nachteil beim Memory-Mapping liegt darin, daß der für die I/O-Operationen
benötigte Speicherplatz den freien Speicher für Programme und deren Daten
verringert.
I/O-Mapped
Eine andere Möglichkeit ist das I/O-Mapping (isolierte Adressierung).
Dabei existieren zwei voneinander getrennte Adreßräume für den Arbeitsspeicher
und den Peripheriespeicher (die I/O-Ports). Durch ein zusätzliches Signal
,,M/ ![]() ``,
welches der Prozessor setzt, wird zwischen den beiden Alternativen unterschieden
und der entsprechende Adreßbereich angesprochen. Die Prozessoren besitzen
zur Adressierung der I/O-Ports eigene Instruktionen (IN/OUT). Bei jedem
Zugriff auf den Speicher oder auf die Peripherie wird durch vorgeschaltete
Adreßdecoder (
``,
welches der Prozessor setzt, wird zwischen den beiden Alternativen unterschieden
und der entsprechende Adreßbereich angesprochen. Die Prozessoren besitzen
zur Adressierung der I/O-Ports eigene Instruktionen (IN/OUT). Bei jedem
Zugriff auf den Speicher oder auf die Peripherie wird durch vorgeschaltete
Adreßdecoder ( ![]() (Chip Select) das Signal ausgewertet.
Ist M/
(Chip Select) das Signal ausgewertet.
Ist M/ ![]() =1,
so bezieht sich der Zugriff auf den Speicherbereich des Arbeitsspeichers.
Bei M/
=1,
so bezieht sich der Zugriff auf den Speicherbereich des Arbeitsspeichers.
Bei M/ ![]() =0 wird auf die Peripherie
(bzw. deren Register) zugegriffen, wobei in der Regel nur der niederwertige
Teil des Adreßbusses benötigt wird. Das liegt daran, weil der Adreßraum
für die I/O wesentlich kleiner ist als der des Arbeitsspeichers. Nachteilig
daran ist die Implementierung der zusätzlichen Signalleitung. Die Firma
INTEL hat sich trotzdem für diese Variante entschieden. Auch wenn ein
Prozessor mit dieser Adressierung versehen ist, besteht selbstverständlich
die Möglichkeit, auch zusätzlich über Memory-Mapped I/O zu adressieren.
=0 wird auf die Peripherie
(bzw. deren Register) zugegriffen, wobei in der Regel nur der niederwertige
Teil des Adreßbusses benötigt wird. Das liegt daran, weil der Adreßraum
für die I/O wesentlich kleiner ist als der des Arbeitsspeichers. Nachteilig
daran ist die Implementierung der zusätzlichen Signalleitung. Die Firma
INTEL hat sich trotzdem für diese Variante entschieden. Auch wenn ein
Prozessor mit dieser Adressierung versehen ist, besteht selbstverständlich
die Möglichkeit, auch zusätzlich über Memory-Mapped I/O zu adressieren.
| Abbildung: Adreßraumvergabe bei I/O-Mapped. Es wird im Vergleich zu Memory-Mapped I/O ein zusätzlicher Adreßraum und damit auch Speicherraum geschaffen. |
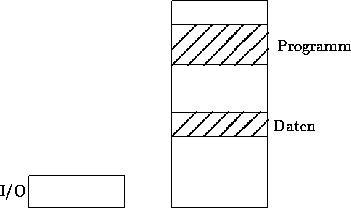 |
| Abbildung: Die I/O-Mapped-Methode benötigt eine spezielle Steuerleitung, um zwischen Speicher- und I/O-Zugriffen zu unterscheiden. |
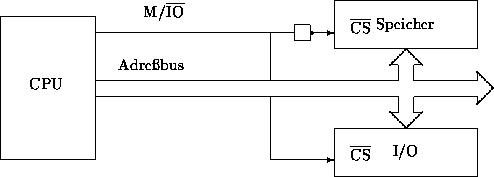 |
IBM entschied sich bei ihrem 8086/8088 für die I/O-Mapped-Methode, die
bis in die heutigen PCs durchgeschleift wurde. Der Befehlssatz der INTEL-Prozessoren
verfügt daher über die speziellen PIO-Befehle IN und OUT. Trotzdem läßt
sich auch Memory-Mapped I/O zur Adressierung verwenden. Störend ist bloß,
daß es außer im Protected Mode keine Verwaltungseinheit für Portadressen
gibt, somit werden auch keine Bereichsüberschreitungen erkannt und gegen
Überschreitung geschützt.
Einmal angenommen, wir betreiben einen Drucker, LPT1, an dem für ihn vom IBM-Standard vorgesehenen Port 378h-37Fh. Wir legen uns aber bald zusätzlich eine Netzwerkkarte zu, die den Port 360h-36Fh bekommt. Bei Netzwerktransfers kann es jedoch passieren, daß der bereitgestellte Speicherplatz als Cache nicht ausreicht; es käme dann zu einer Bereichsüberschreitung. Da es außer im Protected Mode keinen Schutzmechanismus gegen Bereichsüberschreitungen der im Speicher befindlichen Portadressen gibt, kann es durchaus passieren, daß sich die Netzwerkkarte mehr Speicher für ihren Cache raubt, als ihr eigentlich zusteht. Der Drucker macht dann, wenn er denn in Betrieb ist, recht unerwünschte (sonderbare) Dinge.
Beispiel für PIO anhand der Grafikkarte
Eine Grafikkarte beim IBM-PC belegt eine Speicherstelle im RAM, das sogenannte
Video-RAM. Stellen wir uns vor, wir senden der Grafikkarte ordentlich
viele Anweisungen, so kann es passieren, daß die Karte die Daten nicht
so schnell verarbeiten kann wie neue Daten nachkommen. Deswegen bekommt
die Grafikkarte natürlich einen kleinen Pufferspeicher, in dem nach dem
FIFO-Prinzip die ,,zu schnellen Daten`` nacheinander der Grafikkarte zugetrichtert
werden, sobald sie wieder freie Kapazitäten besitzt. Aber auch dann ist
das Risiko zu hoch, schließlich kann auch dieser Puffer nicht immer groß
genug sein. An dieser Stelle zeigt sich, daß der Einschub von Handshaking
(vgl. Abschnitt ![]() ) doch ganz sinnvoll war. Wenden
wir das Handshakingverfahren auf diesen Fall an, so bekommt die Karte
zusätzlich zu dem Datensegment des Memory-Mapped I/O-Ports einen
weiteren Speicherplatz im RAM. Dort halten wir ein Status-Byte für den
jeweiligen I/O-Port bereit, der Auskunft über die belegte Puffergröße
gibt.
) doch ganz sinnvoll war. Wenden
wir das Handshakingverfahren auf diesen Fall an, so bekommt die Karte
zusätzlich zu dem Datensegment des Memory-Mapped I/O-Ports einen
weiteren Speicherplatz im RAM. Dort halten wir ein Status-Byte für den
jeweiligen I/O-Port bereit, der Auskunft über die belegte Puffergröße
gibt.
Polling
Bei allen Systemen, an denen mehrere Peripheriegeräte angeschlossen sind, kommt bei Verwendung von programmierter I/O (PIO) nur das Polling-Verfahren (Abfrageverfahren) in Frage. Jedes Gerät wird über sein Statusregister auf seinen aktuellen Status hin vom Prozessor überprüft, ob das Gerät bereit ist, Daten zu senden oder zu empfangen. Das zu überprüfende Bit nennt man auch das READY-Bit. Befindet sich der Prozessor in einer Polling-Schleife, so ist er ausschließlich damit beschäftigt, nachzufragen, ob ein Gerät Daten senden möchte. Dieser Zustand, der sehr ineffizient ist, wird als Busy Waiting (aktives Warten) bezeichnet (der Prozessor tut nichts anderes, als auf die Bereitschaft der externen Geräte zu warten). Wenn das READY-Bit gesetzt ist, das Gerät also bereit ist, erst dann wird die entsprechende I/O-Aufgabe ausgeführt.
Das Polling ist immer dann zu bevorzugen, wenn ein System blitzschnell auf ein einziges Peripheriegerät zu reagieren hat. Verwendung findet es daher bei Echtzeitanwendungen. Es ist auch dann sinnvoll, wenn der Prozessor keine Aufgaben hat, solange er auf eine Antwort des Peripheriegerätes wartet. Das Polling-Verfahren wird dann ineffizient, wenn mehrere Peripheriegeräte gleichzeitig bedient werden wollen. Das Polling ist daher mit zwei signifikanten Nachteilen behaftet:
- Bei jeder Abfrage des aktuellen Status der I/O-Geräte ,,verschwendet`` der Prozesser Taktzyklen, also Zeit, selbst wenn kein I/O-Gerät einen Prozeß beantragt. (Busy Waiting, aktives Warten)
- Das Verfahren muß bei einem System mit mehreren Peripheriegeräten erst den Status aller Geräte überprüfen, bevor es zur Abarbeitung einer bestimmten Anfrage kommen kann.
Interruptbasierte I/O
Wir suchen also nach einem Verfahren, bei dem der Prozessor besser ausgelastet ist, indem er unnötige Leerlaufzeiten vermeidet und die ,,gesparte Zeit`` anderen Prozessen zur Verfügung stellt. Die Peripheriegeräte sollen aber trotzdem nicht vernachlässigt werden (Quasi-Parallelität).
Quasi-Parallelität
Gäbe es, einmal angenommen, beliebig viele Prozessoren und zwar genau so viele, wie die Anzahl der zur Ausführung bereiten Prozesse, so hätte jeder Prozeß seinen eigenen Prozessor. Da wir aber in der Praxis stets von einem System ausgehen müssen, in dem die Anzahl der in einem bestimmten Zeitpunkt bereiten Prozesse die Anzahl der Prozessoren überschreitet, müssen wir uns einem I/O-Konzept zuwenden, welches den Fall der Parallelität von Prozessen mitberücksichtigt. Ausgangspunkt in den weiteren Betrachtungen soll stets ein Einprozessorsystem sein.
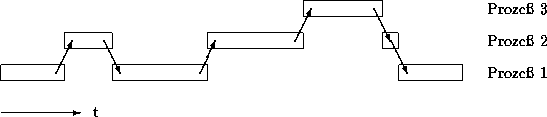
Werden die Prozesse wie in Abbildung ![]() ,,verschachtelt``
und jeweils ,,verzahnt`` ausgeführt, so haben wir eine stückchenweise
Parallelverarbeitung. Man spricht dann auch von Quasi-Parallelität.
Voraussetzung dafür ist allerdings die ,,Unterbrechbarkeit`` des Prozessors
- und damit der einzelnen Prozesse. Eine derart asynchrone Unterbrechung
wird als (Prozessor-)Interrupt bezeichnet. Asynchron daher, weil der Interrupt
nicht synchron, d.h. zu vorhersehbarer Zeit, sondern zu ganz
bestimmten externen Ereignissen - und damit asynchron - eintrifft.
,,verschachtelt``
und jeweils ,,verzahnt`` ausgeführt, so haben wir eine stückchenweise
Parallelverarbeitung. Man spricht dann auch von Quasi-Parallelität.
Voraussetzung dafür ist allerdings die ,,Unterbrechbarkeit`` des Prozessors
- und damit der einzelnen Prozesse. Eine derart asynchrone Unterbrechung
wird als (Prozessor-)Interrupt bezeichnet. Asynchron daher, weil der Interrupt
nicht synchron, d.h. zu vorhersehbarer Zeit, sondern zu ganz
bestimmten externen Ereignissen - und damit asynchron - eintrifft.
Einführung von Interrupts
Nehmen wir einfach mal an, wir hätten ein Telefon ohne Klingel und erwarten ständig wichtige Anrufe. Eine Möglichkeit wäre, den Telefonhörer alle 30 Sekunden abzuheben und zu checken, ob jemand gerade anruft (Polling). Viel sinnvoller ist es doch, eine Klingel zu installieren (Interrupts). Mit Voraussetzung von Quasi-Parallelität ist jetzt folgendes Szenario denkbar: Die Absicht eines oder mehrerer I/O-Prozesse, Prozessorleistung zu erhalten, muß erst beim Prozessor angemeldet werden. Der Vorteil: Die Peripherie wird solange vernachlässigt (ignoriert), bis ein I/O-Gerät für einen Datentransfer bereit ist und dies dem Prozessor durch eine Interrupt-Anforderung (Interrupt-Request, IRQ) wissen läßt. Interrupts werden allgemein unterteilt in:
- Prozessorsynchrone Interrupts. Sie werden durch eine Folge konkreter Befehlsausführungen vom Prozessor selbst ausgelöst, man nennt sie auch Traps. Sie erfolgen selbstverständlich synchron zum Prozessortakt. Bsp.: Division durch Null.
- Prozessorasynchrone Interrupts. Sie werden von der Peripherie ausgelöst. Wenn man allgemein von Interrupts spricht, dann sind damit die prozessorasynchronen Interrupts gemeint. Mit dieser Sorte von Interrupts wollen wir uns im folgenden beschäftigen. Bsp.: Controller-Interrupt.
Der Prozessor wird beim Auftreten eines Interrupts dazu veranlaßt, sein aktuell laufendes Programm (Normalprogramm) zu unterbrechen. Gäbe es nur ein Programm, welches auf jeden Interruptaufruf reagieren soll, so hätten wir gar kein Problem, dieses zu ermitteln. In der Praxis gibt es aber eine Vielzahl solcher Programme, deshalb muß nach Eingang des IRQs getestet werden, welches Programm anstelle des Normalprogramms auszuführen ist. Gehen wir zunächst davon aus, daß es nur einen einzigen IRQ gibt. Dazu muß die Ablaufsteuerung des Fetching (Holephase des Prozessors) um eine Interrupt-Erkennung erweitert werden. Ein IRQ kann, wie wir oben schon festgehalten haben, asynchron, d.h. zu beliebiger Zeit während eines Prozessorzyklus eintreffen. Damit der Prozessor nicht voll und ganz aus der Rolle gebracht wird, wird die Interruptanforderung zunächst zwischengespeichert - man sagt, sie ist hängend (pending). Das Testen des peripheren Signals wird bei neueren Prozessoren hardwareseitig vom Mikroprogramm eines jeden Befehls übernommen. Hierbei wird ein Statusbit abgefragt, das Interrupt-Pending-Bit. Zur Implementierung ist also eine Interruptleitung (INT) nötig, die das Peripheriegerät über einen Interrupt-Controller mit dem Prozessor verbindet. Hinzu kommt noch eine Quittungsleitung (INTA, Interrupt Acknowledge), die den Interrupt bestätigt.
Die Alternative zu dem Hardware-Test ist ein Software-Test, der über
PIO den Zustand der entsprechenden Peripherieregister abfragt (Polling).
Die speziellen Steuerleitungen zum Prozessor sind dann zwar nicht nötig,
aber ein solcher Interrupt-Handler ist wegen den in Abschnitt
![]() bereits genannten Performance-Gründen
nicht angebracht.
bereits genannten Performance-Gründen
nicht angebracht.
Interrupt-Service-Routine
Heutzutage ist es undenkbar, nur eine einzige Interruptanfrage bearbeiten zu können. Es wird nach einem Verfahren gesucht, welches es ermöglicht, auch mehrere unterschiedliche Interruptquellen zu gestatten. Unabhängig von der Art des Tests (Soft- oder Hardware) springt der Prozessor zu einem Programm, das der Interruptquelle zugeordnet ist. Diese Ausnahmeroutine bezeichnet man als die (Interrupt-)Service-Routine, ISR. Eine ISR ist eine Art Unterprogramm, welches sich an einer bestimmten Stelle im Speicher befindet.
Ähnlich laufen auch die Unterprogrammaufrufe durch CALL- und RETURN-Befehle ab. Durch das IRQ-Signal (entspricht dem CALL) wird zu einer bestimmten ISR verzweigt und die Rücksprungadresse zum bisherigen Prozeß auf dem Stack abgelegt. RETURN bewirkt die Rückkehr. Damit es zu keinen Konflikten mit den aktuellen Statusregistern des Prozessors kommt, muß ein ein Unterprogramm in einer ISR reentrant (wiedereintrittsfest) sein. Konkret heißt das, daß am Anfang der ISR die Statusregister und der Programmzähler auf dem Stack abgelegt werden. Vor der Rückkehr werden diese wieder vom Stack zurückgelesen. Es gibt einen speziellen RETURN-Befehl für Interrupts, den EOI-Befehl (End Of Interrupt).
Nachdem die Service-Routine abgearbeitet worden ist, kehrt der Prozessor
wieder an die Stelle im Normalprogramm zurück, das er abgearbeitet hatte,
bevor der Interrupt einsetzte. Nun wird das Normalprogramm reaktiviert.
Der Aufruf von Interrupts ist daher schematisch gleichbedeutend mit der
Quasi-Parallelverarbeitung von Prozessen (vgl. Abbildung ![]() ).
).
Vektortabelle
Die Vektortabelle enthält die Startadressen der Interrupt-Service-Routinen.
Die Indizes werden Vektornummern (VN) genannt. Die (Interrupt-)Vektortabelle
ist meistens im unteren Adreßbereich des Hauptspeichers abgelegt und besitzt
die Offset-Adressen 0000 bis 1023. Es ergeben sich 256 verschiedene Vektoreinträge,
wenn jeder Eintrag 4 Byte groß ist. Besitzt man bereits die Vektornummer,
so kann man daraus die Offsetstartadresse der ISR berechnen:
![]()
Abbildung: Vektortabelle beim IBM-PC/AT
|
Wie in der Vektortabelle eines üblichen IBM-PC/AT in Abbildung ![]() zu ersehen ist, befinden sich die Startadressen
der ISR, die sich in erster Linie um die Überwachung des System kümmern
(u.a. Traps) unter den obersten Tabellenplätzen. Anschließend folgen
diejenigen, die für bestimmte Hardware-Komponenten reserviert sind (u.a.
FPU, MMU). Bei jedem Auftreten eines maskierbaren5
Interrupts prüft der Prozessor zunächst, ob das Interrupt Enable
Bit (IEB) in seinem Statusregister gesetzt ist. Erst wenn dies
der Fall ist, gibt der Prozessor das INTA-Signal (Interrupt Acknowledge)
an den Interrupt-Controller durch (vgl. Abschnitt
zu ersehen ist, befinden sich die Startadressen
der ISR, die sich in erster Linie um die Überwachung des System kümmern
(u.a. Traps) unter den obersten Tabellenplätzen. Anschließend folgen
diejenigen, die für bestimmte Hardware-Komponenten reserviert sind (u.a.
FPU, MMU). Bei jedem Auftreten eines maskierbaren5
Interrupts prüft der Prozessor zunächst, ob das Interrupt Enable
Bit (IEB) in seinem Statusregister gesetzt ist. Erst wenn dies
der Fall ist, gibt der Prozessor das INTA-Signal (Interrupt Acknowledge)
an den Interrupt-Controller durch (vgl. Abschnitt ![]() ).
).
Vektorisierung
Das Verzweigen zur Interrupt-Service-Routine wird allgemein mit Vektorisierung von Interrupts bezeichnet. Bei der Vektorisierung gibt es viele Möglichkeiten, von denen hier die wichtigsten vorgestellt werden [3]:
- 1.
- Die Interruptquelle legt den CALL-Befehl auf den Datenbus. Dieser wird vom Prozessor gelesen und wird daraufhin decodiert und ausgeführt.

- 2.
- Die Interruptquelle legt nicht den CALL-Befehl selbst, sondern seine (Speicher-)Adresse auf den Datenbus. Der Prozessor liest mit dieser Adresse den CALL-Befehl aus dem Speicher, decodiert den Befehl und führt ihn aus.

- 3.
- Anstelle des ganzen Befehls legt die Interruptquelle nur die im benötigten Befehl befindliche Adresse auf den Datenbus. Dies ist schließlich gleich der Adresse der Service-Routine. Der Prozessor liest die Service-Routine und verzweigt direkt zum Mikroprogramm des CALL-Befehls (oder gar zu einem bestimmten Mikroprogramm für den Interrupt). Die Decodierung entfällt.
- 4.
- Statt der Adresse der Service-Routine wird nur die Vektornummer
auf den Datenbus gelegt. Durch den Interrupt wird die Vektornummer
bestimmt. In der im Speicher befindlichen Vektortabelle werden
die Startadressen der jeweiligen Service-Routinen festgehalten. (Vgl.
Abschnitt ).
Die Adresse der Service-Routine wird vom Prozessor aus dem Speicher
gelesen und verzweigt direkt zum Mikroprogramm des CALL-Befehls (oder
zu einem bestimmen Mikroprogramm für den Interrupt). Solche Interrupts
nennt man Vektor-Interrupts.
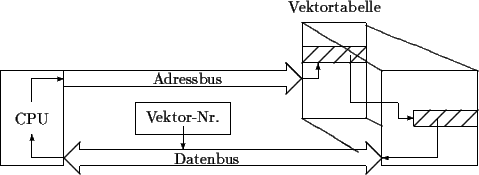
- 5.
- Anders als in 4. legt die Interruptquelle keine Angabe für die Service-Routine auf den Datenbus. Die Vektornummer ist für den jeweiligen Interrupt prozessorintern gespeichert, so daß sie nicht erst (prozessorextern, z.B. über den Speicher) gelesen werden muß. Der Prozessor benutzt die Vektornummer unmittelbar zur Indizierung der Vektortabelle. Man nennt diese Interrupts Autovektor-Interrupts.

In der Praxis wird die Vektormethode 4. und 5. am häufigsten eingesetzt. Durch sie entsteht ein großer Hardware-Aufwand, da für jede Interrupt-Anforderung ein Eingang am Prozessor vorgesehen sein muß.
Flexibler sind jedoch die ersten drei Methoden, weil mehrere mögliche ISR auf einen einzigen Interrupt angewendet werden können. Die Effizienz ist allerdings geringer.
Maskierung
Wenn durch einen Interrupt das Interruptsignal INT=1 gesetzt ist, kann es bei einem Hardwaretest zu Problemen führen. Im unmittelbaren Befehlszyklus nach Ausführung der Service-Routine wird wieder derselbe Interrupt ausgelöst, auch wenn die Peripherie diesen nicht erwünscht hat. Folglich muß ein zusätzliches Bit untergebracht werden, welches das Interruptsignal unwirksam macht. Ein solches Bit heißt Maskenbit, da das Interruptsignal ,,maskiert`` wird. Für den Prozessor ist das Interruptsignal, solange es maskiert ist, praktisch unsichtbar. Das Entfernen (,,Demaskieren``) des Interrupts sollte erst nach Abarbeitung der Service-Routine erfolgen, da damit zeitgleich auch das Interrupt-Pending-Bit gelöscht wird.
Neben den maskierbaren Interrupts gibt es aber auch solche, die sich nicht maskieren lassen. Es handelt sich um nicht-maskierbare Interrupts (NMI). Wie der Name schon andeutet, können NMIs nicht ausmaskiert werden. Auch die Software besitzt keine Möglichkeit, diese Interrupts zu unterbinden. Sie sind in der Lage, bereits laufende (maskierbare) Interrupts zu unterbrechen. NMIs haben stets die höchste Priorität und sind nur für die schlimmsten Ereignisse konzipiert worden. Ausgelöst werden sie z.B. bei unmittelbar bevorstehendem Stromverlust oder bei Speicher(zugriffs)fehlern (Page Faults).
Interrupt-Controller 8259 PIC
Um die theoretischen Kenntnisse nun einmal in der Praxis zu sehen, wird hier der Interrupt-Controller 8259 PIC von INTEL vorgestellt.
| Abbildung: Stark vereinfachter Aufbau des 8259 PIC Interrupt-Controller von INTEL und dessen Anbindung an einen Prozessor |
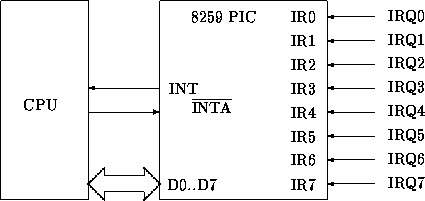 |
Sein Aufbau und seine Funktionsweise ist sehr trivial und daher leicht
nachzuvollziehen. Aber dennoch verfügt er über alle bisher besprochenen
Features. Er kann einzeln bis zu 8 externe Interruptquellen verwalten,
kann diese priorisieren, maskieren und erkennt, welche Interrupts gerade
hängend (pending) sind und welcher gerade bedient (ge,,service``d)
wird.
Das Innenleben des 8259 PIC
|
Abbildung: Die codierte Interrupt-Vektornummer ist
in den niederwertigen 3 Bits angegeben. Die 5 übrigen Bits dienen
als Offset des ersten IRQ (IRQ0) in der Vektortabelle, der bei Initialisierung
des Interrupt-Controllers geändert werden kann ( |
 |
Der Prozessor holt die Interrupt-Vektornummer vom Datenbus und ruft
die entsprechende Interrupt-Service-Routine auf. Nach Beenden der Service-Routine
wird ein EOI-Befehl an den Controller übergeben. Das ISR-Bit wird dann
gelöscht. In einer anderen Betriebsart, die den Normalfall darstellt,
wird direkt beim Ausklingen des zweiten ![]() -Signals das ISR-Bit
automatisch gelöscht. Befindet sich noch ein gesetztes Bit im PR, so
beginnt dieser Vorgang von vorn. Eine Ausnahme besteht dann, wenn der
PR erkennt, daß während einer ,,Bedienung`` eines Interrupts durch die
Service-Routine ein Interrupt höherer Priorität angefordert wird. In
diesem Fall wird die Service-Routine - entsprechend dem Abbruch eines
Normalprogramms - abgebrochen und die neue Routine aufgerufen.
-Signals das ISR-Bit
automatisch gelöscht. Befindet sich noch ein gesetztes Bit im PR, so
beginnt dieser Vorgang von vorn. Eine Ausnahme besteht dann, wenn der
PR erkennt, daß während einer ,,Bedienung`` eines Interrupts durch die
Service-Routine ein Interrupt höherer Priorität angefordert wird. In
diesem Fall wird die Service-Routine - entsprechend dem Abbruch eines
Normalprogramms - abgebrochen und die neue Routine aufgerufen.
Kaskadierung zweier 8259 PIC Interrupt-Controller

Der ursprüngliche 8-Bit IBM-PC und der PC/XT besaßen nur einen einzigen PIC, daher konnten nur 8 Hardware-Interrupts unterstützt werden. Wenig später, mit dem IBM PC/AT 16-Bit ISA-Bus, wurde aus Gründen der Abwärtskompatibilität ein zweiter PIC mit dem bereits vorhandenen zusammengeschaltet (,,kaskadiert``).
Da die INTEL 80x86-Prozessorserie aber nur über eine einzige INT-Leitung verfügt, wurde der zweite PIC (PIC2) an den IRQ2-Anschluß des ersten PIC (PIC1) angeschlossen. Folglich sind insgesamt 15 Hardware-Interrupts implementiert.
Sind in einem System zwei PIC Interrupt-Controller kaskadiert, so ist
einer Master und der andere Slave. Erreichen den Master Interruptanforderungen
auf den Leitungen IRi, ändert sich nichts im Vergleich
zu einem Single-Betrieb. Wenn eine Anforderung auf die Leitungen des
Slave eintrifft, dann wird INT signalisiert. INT ist nicht - wie bisher
- mit dem Prozessor, sondern mit dem Master-PIC verbunden. Im IRR-Register
wird das 2. Bit gesetzt und gegen die ISR- und IMR-Register verglichen.
Anschließend, wenn nichts dagegen spricht, wird der Slave durch die
CASi-Leitungen ,,aktiviert``. Wenn im folgenden der
Prozessor sein ![]() -Signal setzt, um den Interrupt zu bestätigen, fühlt
sich nur der Slave davon angesprochen. Der Master ,,ruht`` währenddessen.
Der Rest geschieht analog zum Single-Betrieb.
-Signal setzt, um den Interrupt zu bestätigen, fühlt
sich nur der Slave davon angesprochen. Der Master ,,ruht`` währenddessen.
Der Rest geschieht analog zum Single-Betrieb.
Es ist natürlich denkbar, bis zu 8 Slaves an einem Master zu betreiben. In diesem Fall kann man bis zu 64 Interrupts verwalten.
Wegen Kaskadierung der beiden PICs ab dem IBM PC/AT ergeben sich Änderungen in der Reihenfolge der Prioritäten. IRQ0 besitzt jedoch in beiden Fällen stets die höchste und IRQ7 ebenfalls die niedrigste Priorität. Während beim PC/XT die Prioritätsreihenfolge 0, 1, 2, 3, 4, 5, 6, 7 ist, sieht sie bei dem PC/AT so aus: 0, 1, 8, (2/9), 10, 11, 12, 13, 14, 15, 3, 4, 5, 6, 7. Bei den heutigen PCs macht sich die Prioritätsreihenfolge so gut wie überhaupt nicht bemerkbar, weshalb es prinzipiell egal ist, welche Interruptnummern man für die Geräte vergibt.
|
DMA (Direct Memory Access)
Wir suchen nun nach einer effektiveren Lösung, die Daten von den Peripheriegeräten zum Speicher und zurück zu transportieren. Bisher war der Prozessor stets im Mittelpunkt des Geschehens. Durch ihn bzw. durch seine internen Register wurde der Transport abgewickelt. Während des Datentransports der Datenblöcke wurde der Prozessor bisher stets von seiner ursprünglichen Tätigkeit abgehalten. Und dies auch, wenn die zu übertragenden Datenblöcke für die CPU an Bedeutung verloren haben bzw. nie Bedeutung hatten. Dazu zählt z.B. das Ausgeben von bereits verarbeiteten Daten auf einen Datenträger oder den Drucker. Die CPU wird dabei ständig durch Interrupt-Anforderungen unterbrochen und befindet sich im Moment der Übertragung im Leerlauf. Abhilfe schafft das Konzept des direkten Speicherzugriffs (Direct Memory Access, DMA). DMA ist der direkte Zugriff auf den Speicher ohne CPU-Beteiligung. Die Datenübertragung zwischen dem Speicher und den Peripheriegeräten wird durch einen speziellen DMA-Baustein, den DMA-Controller, übernommen. Anders als bei der CPU geht die Übertragung der Daten(blöcke) nicht über interne Register, sondern direkt über den Datenbus (einzige Ausnahme: bei Speicher-Speicher-Übertragungen). Der DMA-Controller hat daher eher Steuerungsfunktion und ist für die Ausgabe der entsprechenden Adreß- und Steuersignale zuständig.
Ähnlich wie bei den Interrupts bekommen die Peripheriegeräte eine Möglichkeit, die Aufmerksamkeit auf sich zu ziehen. Irreführenderweise nennt man diese Verbindungen Kanäle. Anforderungen der Peripherie werden durch die Kanäle über ein DREQ-Signal (DMA-Request) an die DMA gerichtet.
Die DMA unterstützt folgende Übertragungsmöglichkeiten:
- Speicher
 Peripherie
Peripherie - Peripherie Peripherie
- (Speicher Speicher)
U.a. sinnvoll zum ,,Refreshen`` der Speicherbausteine
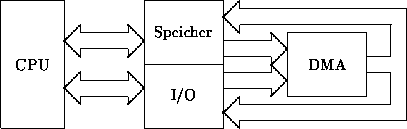
Bus-Arbitration
Jetzt sind mehrere Komponenten des Systems fähig, selbständig auf den Systembus zugreifen zu können. Solche Komponenten werden als Busmaster bezeichnet. Doch bevor die Busmaster einen Zugriff genehmigt bekommen, müssen sie einen Arbiter (Schiedsrichter) darum bitten. Dieser erteilt ihnen dann die Erlaubnis (oder auch nicht). Erhalten sie die Erlaubnis, so übernehmen die Busmaster die vorübergehende Kontrolle über den Systembus. Ein solches Verfahren der Zugriffsgenehmigung nennt man Bus Arbitration Control. Auch hier findet das Handshaking wieder Anwendung. Wir benötigen diesmal zwei (bei Mehrmastersystemen6 sogar drei) Signalleitungen.
- HRQ
- Durch dieses Signal wird dem Prozessor bzw. dem Arbiter mitgeteilt, daß eine andere Komponente den Systembus benutzen möchte. Daraufhin führt der Prozessor bzw. der zuletzt aktive Busmaster seine aktuell durchgeführte Operation auf dem Systembus (Lese- oder Schreibzugriff) zu Ende.
- HLDA
- Hat der Prozessor bzw. zuletzt aktive Busmaster seinen Systembus-Zugriff beendet, so teilt er der anfordernden Komponente über das HLDA-Signal die Freigabe des Busses mit. Solange der Bus freigegeben ist, kann der Prozessor bzw. der zuletzt aktive Busmaster natürlich weitere Berechnungen durchführen, allerdings nicht auf den Systembus zugreifen. Er wartet dann solange, bis der Bus wieder freigegeben ist.
- BGA
- Geben bei einem Mehrmastersystem mehrere Komponenten gleichzeitig ihre Anforderung durch ein HRQ-Signal ab, so muß nach einem bestimmten Verfahren durch einen sogenannten Bus (Hold) Arbiter (,,Schiedsrichter``) eine Komponente zum aktiven Busmaster gewählt werden. Das BGA-Signal (,,Bus Grant Acknowledge``) gibt den einzelnen Busmastern Auskunft darüber, wann sie drankommen. Ein solches Verfahren ist das Daisy Chaining und macht nur in Mehrmastersystemen Sinn. Es sollte allein der Vollständigkeit halber hier erwähnt werden. Beim AT wurde erstmals die Busmastering-DMA eingeführt. Dahinter steckt die Fähigkeit von Erweiterungskarten eine externe Aufforderung an den Bus zu erteilen. Die DMA-Bausteine tauchen demnach auch auf den Erweiterungskarten auf. Ab dem EISA- und MCA-Bus wurde dieses Konzept völlig neu überarbeitet. Es können seitdem auch nicht-DMA-Buszugriffe extern, d.h. über eine busmasterfähige Erweiterungskarte erfolgen. Von der Hardwareseite aus wurden Interrupt- und DMA-Kanäle ebenfalls neu zugewiesen - eine I/O-Revolution sozusagen.
DMA-Controller 8237

Kaskadierung zweier DMA-Controller
| Abbildung: Wie bei der Kaskadierung von zwei Interrupt-Controllern beim AT, werden auch hier zwei DMA-Controller 8237 zusammengeschaltet |
 |
Die Kaskadierung von DMA-Controllern der Serie 8237 entspricht weitestgehend
dem Vorgehen wie bei dem 8259 PIC erklärt wurde, jedoch mit dem wesentlichen
Unterschied, daß beliebig viele DMA-Controller kaskadiert werden können.
Während beim XT der DMA-Controller nur über 8 Bit große DMA-Kanäle
verfügte, wurden beim AT zusätzlich vier 16 Bit Kanäle hinzu,,kaskadiert``.
Näher möchte ich aber an dieser Stelle nicht auf die DMA-Kaskadierung
eingehen. Es folgt lediglich eine kleine Übersicht einer typischen Belegung
beim AT:
|
Beim XT im Single-Betrieb wurde Kanal 3 noch für den Festplattencontroller standardmäßig verwendet.
Prinzipieller Aufbau

Es kann wegen der Einteilung in DMA-Pages zu DMA-Segmentüberläufen kommen,
wenn man versucht, über die Page-Grenzen hinaus Daten zu übertragen.
Dann nämlich wird der Rest der Daten an den Anfang der DMA-Page geschrieben.
Der DMA-Controller gibt keine Warnungen bei bevvorstehenden Segmentüberläufen
aus.
DMA-Betriebsarten
Den DMA-Controller kann man in verschiedenen Betriebsarten betreiben, die sich hinsichtlich der Systembusbelegung unterscheiden.
Single Mode (Cycle Stealing)
Beim Single Mode überträgt der DMA-Controller bei jedem ,,Durchgang`` nur ein einziges Byte. Nach jedem Durchgang wird der Systembus wieder an den Prozessor freigegeben. Dieser Modus heißt deswegen auch Cycle Stealing, weil dem Prozessor bei jedem Übertragungsvorgang für einige Taktzyklen der Systembus kurz entzogen wird.
Anschließend löst der TC eine Autoinitialisierung aus. Nachteilig daran ist, daß nach jedem Transfer erneut die Erlaubnis über den Systembus erteilt werden muß. Wie wir am obigen Beispiel des FDC gesehen haben, wird dieser Modus bei Übertragungen von Diskettensektoren verwendet.
Burst Mode (Block Transfer Mode)
Im Burst Mode überträgt der Controller alle Daten im gewünschten
Block, ohne dabei den Systembus zwischenzeitlich freizugeben. Der DMA-Controller
gibt den Bus erst dann wieder frei, wenn das Zählregister von 0000h
auf FFFFh umspringt oder ein externes ![]() erfolgt.
erfolgt.
Demand Transfer Mode
Der Demand Transfer Mode (Transfer auf Anforderung) ist eher
eine Art Mischung aus den ersten beiden Betriebsarten. Der DMA-Controller
führt solange die Datenübertragung aus, bis entweder ein ![]() oder das Peripheriegerät DREQ deaktiviert.
Beim Burst Mode hat das Deaktivieren des DREQ-Signals keinerlei
Auswirkungen.
oder das Peripheriegerät DREQ deaktiviert.
Beim Burst Mode hat das Deaktivieren des DREQ-Signals keinerlei
Auswirkungen.
IOP (I/O-Prozessoren)
Obwohl in der Fachliteratur oft bei DMA-Controllern die Rede von sogenannten I/O-Prozessoren (IOP) ist, muß an dieser Stelle diese Auffassung streng kritisiert werden. Üblicherweise spricht man bei den Eingängen des DMA-Controllers zwar von Kanälen, diese haben jedoch nichts mit den I/O-Prozessorkanälen zu tun. Es erscheint daher sinnvoll, kurz auf das I/O-Prozessorkonzept einzugehen, um auf diese Unklarheiten einzugehen.
Ein DMA-Controller entlastet den Prozessor (CPU) zwar von dem eigentlichen
Datentransfer, nicht aber von der Gerätesteuerung. Bei DMA ist es immer
noch die CPU, die auf eventuelle Zustandsänderungen der Peripheriegeräte
hin Aktionen durchführen muß. Auch bei komplizierten Adreßberechnungen
ist die CPU im Spiel. Die CPU ist bei DMA also sozusagen das Kontrollzentrum.
Der I/O-Prozessor übernimmt diese Kontrollfunktion im weitesten Sinne.
Wie bei den DMA-Controllern fordern die I/O-Prozessoren den Systembus
an und muß ihnen erst genehmigt werden (vgl. Bus-Arbitration in Abschnitt
![]() ). Er wird als Coprozessor am Systembus angeschlossen
und von der CPU lediglich veranlaßt, selbständig I/O-Programme auszuführen.
). Er wird als Coprozessor am Systembus angeschlossen
und von der CPU lediglich veranlaßt, selbständig I/O-Programme auszuführen.
Die I/O-Programme stehen an bestimmten Stellen im Speicher; solche Programme sind nichts anderes als Device Driver. Im Vergleich zur CPU verfügt der IOP nur über eine geringe Zahl an Befehlen, dazu zählen:
- Transferbefehle
- Befehle zur Gerätesteuerung
- Verzweigungsbefehle
- Arithmetikbefehle
Anders als die DMA-Controller sind die I/O-Prozessoren an zwei unterschiedliche Busarten angeschlossen. Zum einen ist es der Systembus, über den die Kommunikation und der Datenaustausch stattfindet, zum anderen ein I/O-Bus, der die Peripherie mit dem I/O-Prozessor verbindet.
Schlußwort
Es folgt ein Zitat aus [1]:
Interrupts considered harmful
Each aspect of life can be divided into one of two categories: a good thing or a bad thing. There are those who are firmly convinced that interrupts are a bad thing. A single interface generating the occasional interrupt causes few headaches. But imagine a system with many interfaces, all generating their interrupts asynchronously (i.e. at random). The entire system no longer behaves in a deterministic way but becomes stochastic (non-deterministic) and is best described by the mathematics of random processes. This system is analogous to a large group of people in a bar - there is always someone who never seems to get served.
Alan Clements
Fußnoten
- ... eingegangen.1
- Wenn im folgenden von Zugriffen auf die Peripheriegeräte die Rede ist, dann wird damit natürlich die Schnittstelle umgangen. Wir betrachten sie daher schlicht und ergreifend als ein ,,transparentes Medium``.
- ... worden)2
- Vgl. ,,Speicherverwaltung``
- ... Systembus3
- Systembus ist ein Oberbegriff für Adreß-, Daten-, Steuerbus zusammen.
- ... I/O-Methode4
- Memory-Mapped I/O ist nicht zu verwechseln mit Memory Map, einem Speicherplan, der angibt, wo sich die unterschiedlichen Segmente (RAM-, ROM-, Programm-, Datenbereiche, etc.) im Speicher befinden
- ... maskierbaren5
- Vgl. Maskierung von Interrupts in Abschnitt .
- ... Mehrmastersystemen6
- Der Begriff des Mehrmastersystems sollte zunächst definiert
werden: Existieren neben dem Haupt-Prozessor (CPU) keine weiteren
programmierbaren Master (etwa: I/O-Prozessoren, vgl. Abschnitt ), sondern nur nichtprogrammierbare
Master (etwa: Interrupt- oder DMA-Controller), dann nennt man das
System ein Einmastersystem. Obwohl auch die Controller programmierbar
sind, so sind sie es nur aufgrund von Steuerinformationen, laufen
aber nicht selbständig ab. Folglich existiert dann ein Mehrmastersystem,
wenn mehr als ein programmierbarer Master vorhanden ist.
Literatur
- [1]
- Alan Clements, "The Principles of Computer Hardware",
Oxford University Press, 2nd edition 1992 - [2]
- Nikitas Alexandridis, "Design of Microprocessor-Based Systems",
Prentice-Hall New Jersey, 1st edition 1993 - [3]
- Liebig/Flik, "Rechnerorganisation",
Springer-Verlag Berlin Heidelberg, 2. Auflage 1993 - [4]
- Tischer/Jennrich, "PC Intern 5"
Data Becker GmbH & Co. KG Düsseldorf, 1. Auflage 1995 - [5]
- Löffler/Meinhardt/Werner, "Taschenbuch der Informatik",
Fachbuchverlag Leipzig, 1. Auflage 1992 - [6]
- Bähring, "Mikrorechnersysteme",
Springer-Verlag Berlin Heidelberg, 1. Auflage 1991 - [7]
- Speedboy, "E/A und Interrupts",
http://hyperg.uni-paderborn.de/ra_skript_inter;internal&sk=ROBOT - [8]
- Hans-Peter Messmer, "PC-Hardwarebuch",
Addison-Wesley, 5. Auflage 1997
Das Hosting wird gesponsort von: Webstrategy GmbH, Kronberg im Taunus